| |  |
| |
QNX: QNX NEUTRINO RTOS V 6.2
Содержание
4.6 Семафоры
Тесты в разделах 4.6.1, 4.6.2 и 4.6.3 обрабатывают создание и удаление семафоров. Пиковые значения результатов тестов связаны с прерываниями таймера, происходившими каждую миллисекунду во время измерений. Также рассматривается тот факт, что время удаления семафора не зависит от того, был он использован или нет. Т.е. предполагается, что при поступлении запроса на создание семафора все необходимые ресурсы уже выделены.
Тест синхронизации, результаты которого представлены в разделе 4.6.6, создает ситуацию, в которой несколько разноприоритетных нитей ожидают сигнала одного и того же семафора. В QNX NEUTRINO RTOS v6.2 существует 64 уровня приоритетов. Поскольку самый низкий уровень зарезервирован на задание «простоя» и не может быть использован приложениями, тест проводился с использованием 63 нитей.
 Идея теста заключается в том, чтобы проверить, зависит ли сумма времени освобождения и времени переупорядочивания от числа ожидающих сигнала семафора нитей. Как показывают результаты теста, представленные на рисунке 4.6-12, для QNX NEUTRINO RTOS v6.2 такой зависимости нет. Измеряемые значения остаются постоянными для цикла тестов с числом ожидающих семафора нитей, варьирующимся от 1 до 63. Идея теста заключается в том, чтобы проверить, зависит ли сумма времени освобождения и времени переупорядочивания от числа ожидающих сигнала семафора нитей. Как показывают результаты теста, представленные на рисунке 4.6-12, для QNX NEUTRINO RTOS v6.2 такой зависимости нет. Измеряемые значения остаются постоянными для цикла тестов с числом ожидающих семафора нитей, варьирующимся от 1 до 63.
В QNX NEUTRINO RTOS v6.2 сумма времени освобождения и времени переупорядочивания является независимой от числа ожидающих одного и того же семафора нитей. Возможно, это означает, что система пересортировывает очередь ожидающих семафора нитей при каждом добавлении в нее новой нити. Результаты тестирования синхронизации были обработаны повторно для получения времени, которое требуется системе для того, чтобы захватить не сигнализирующий семафор и произвести переупорядочивание заданий, для запуска следующей нити (см. раздел 4.6.7). Всякий раз, когда нить пытается захватить не сигнализирующий семафор, она добавляется в очередь семафора. Цель этого испытания состоит в том, чтобы проверить, что время добавления новой нити в очередь семафора (и сортировки очереди!!) независимо от числа нитей в очереди.
Результаты представленные на рис. 4.6-14 (стр. 68) показывают, что никакой зависимости между временем сортировки очереди и числом нитей в ней нет.
4.6.1 Создание (SEO-a-1.d)
- Число нитей: 1
- Модель памяти: d
| Число опытов | Минимальное (мкс) | Максимальное (мкс) | Среднее (мкс) | | 8192 | 3.4 | 8.5 | 3.4 |
|
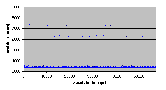
Рис. 4.6-1 SEO-a-1.d
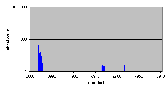
Рис. 4.6-2 SEO-a-1.d - распределение частоты
4.6.2 Удаление (SEO-b-1.d)
- Число нитей: 1
- Модель памяти: d
| Число опытов | Минимальное (мкс) | Максимальное (мкс) | Среднее (мкс) | | 8191 | 3.2 | 10.2 | 3.2 |
|
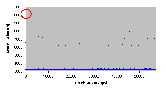
Рис. 4.6-3 SEO-b-1.d
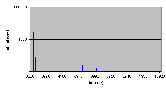
Рис. 4.6-4 SEO-b-1.d - распределение частоты
4.6.3 Удаление после использования (SEO-c-1.d)
- Число нитей: 1
- Модель памяти: d
| Число опытов | Минимальное (мкс) | Максимальное (мкс) | Среднее (мкс) | | 8191 | 3.2 | 10.2 | 3.2 |
|
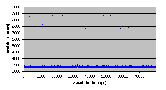
Рис. 4.6-5 SEO-c-1.d
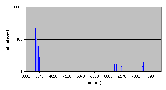
Рис. 4.6-6 SEO-c-1.d - распределение частоты
4.6.4 Отсутствие разногласий – Захват (SEO-d-1.d)
- Число нитей: 1
- Модель памяти: d
| Число опытов | Минимальное (мкс) | Максимальное (мкс) | Среднее (мкс) | | 8192 | 2.5 | 9.1 | 2.5 |
|
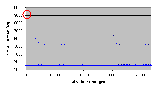
Рис. 4.6-7 SEO-d-1.d
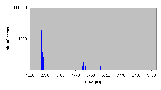
Рис. 4.6-8 SEO-d-1.d - распределение частоты
4.6.5 Отсутствие разногласий – Освобождение (SEO-e-1.d)
- Число нитей: 1
- Модель памяти: d
| Число опытов | Минимальное (мкс) | Максимальное (мкс) | Среднее (мкс) | | 8191 | 2.4 | 6.4 | 2.4 |
|
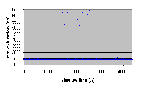
Рис. 4.6-9 SEO-e-1.d
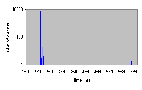
Рис. 4.6-10 SEO-e-1.d - распределение частоты
4.6.6 Синхронизация (SEO-f-63.d)
- Число нитей: 63
- Модель памяти: d
| Число опытов | Минимальное (мкс) | Максимальное (мкс) | Среднее (мкс) | | 8273 | 5.9 | 12.7 | 6.6 |
|
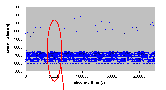
Рис. 4.6-11 SEO-f-63.d
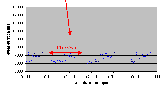
Рис. 4.6-12 SEO-f-63.d – Покомпонентное изображение
4.6.7 Захват несигнализирующим семафором
- Число нитей: 247
- Модель памяти: d
| Число опытов | Минимальное (мкс) | Максимальное (мкс) | Среднее (мкс) | | 8273 | 5.7 | 11.7 | 6.7 |
|
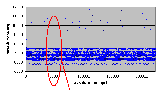
Рис. 4.6-13 Захват несигнализирующим семафором
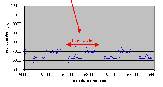
Рис. 4.6-14 Захват несигнализирующим семафором – покомпонентное изображение
4.7 Мьютексы
Данный тест несвязанных между собой захватов и освобождений мьютекса, результаты которого представлены в разделах 4.7.1 и 4.7.2, реализован в виде непрекращающегося цикла захватов и мгновенно следующих за ними освобождений мьютекса.
В QNX NEUTRINO RTOS v6.2 реализован весьма критичный для RTOS механизм наследования приоритетов. Он протестирован путем создания 3 нитей, для которых сразу же возникла проблема инверсии приоритетов: нить с высоким уровнем приоритета претендовала на захват мьютекса, которым уже владела нить с более низким приоритетом, в свою очередь, нить со средним уровнем приоритета не давала запуститься нити с низким приоритетом и освободить мьютекс. Т.о., высокоприоритетная нить не могла захватить мьютекс.
В данном тесте оценено время, которое требуется высокоприоритетной нити для захвата мьютекса. В это время включалось время повышения приоритета низкоприоритетной нити, освобождение ею мьютекса и переключение на высокоприоритетную нить для предоставления ей возможности захватить мьютекс.
Рис. 4.7-5 (стр. 72) показывает, что механизм наследования приоритетов является стабильным: максимальное время для совершения этой серии операции не превышало 14мкс. И по-прежнему прерывания от таймера являлись причиной случайных выбросов.
Данный тест показывает значительные улучшения в системе, по сравнению с предшествующей версией. Очевидно, что проблема инверсии приоритетов является худшим случаем развития событий в системе реального времени. Сценарий развития событий в подобной ситуации был улучшен более чем на 30% по сравнению с предыдущей версией.
| Версия | Минимальное (мкс) | Максимальное (мкс) | Среднее (мкс) | | QNX 6.1 | 11.6 | 19.0 | 11.9 | | QNX 6.2 | 7.1 | 13.7 | 7.4 |
|
4.7.1 Отсутствие разногласий – Захват (SEO-d-1.d)
- Число нитей: 1
- Модель памяти: d
| Число опытов | Минимальное (мкс) | Максимальное (мкс) | Среднее (мкс) | | 8192 | 0.4 | 9.6 | 0.4 |
|
Рис. 4.7-1 SEO-d-1.d
Рис. 4.7-2 SEO-d-1.d - распределение частоты
4.7.2 Отсутствие разногласий – Освобождение (SEO-e-1.d)
- Число нитей: 1
- Модель памяти: d
| Число опытов | Минимальное (мкс) | Максимальное (мкс) | Среднее (мкс) | | 8191 | 0.4 | 7.2 | 0.5 |
|
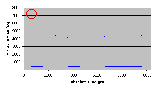
Рис. 4.7-3 SEO-e-1.d
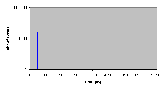
Рис. 4.7-4 SEO-e-1.d - распределение частоты
4.7.3 Инверсия приоритетов (SEO-g-3.d)
- Число нитей: 3
- Модель памяти: d
| Число опытов | Минимальное (мкс) | Максимальное (мкс) | Среднее (мкс) | | 10922 | 7.1 | 13.7 | 7.4 |
|
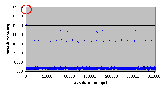
Рис. 4.7-5 SEO-g-3.d
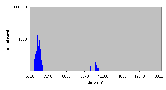
Рис. 4.7-6 SEO-g-3.d - распределение частоты
4.8 Файловая система – права доступа
Тесты данного раздела оценивают производительность файловой системы QNX.
Сначала мы оценили время создания и удаления файлов. Средним временем создания файла было 5 мс, максимальное время создания составило около 15 мс. Данное максимальное значение было получено при проведении первой последовательности тестов.
Было проведено по три теста на чтение и запись в файл. Различие в проводимых тестах заключалось в размере обрабатываемых данных - 1 байт (1), 1 блок размером в 512 байтов (1b) и 10 блоков размером в 5120 байтов (10b). Была использована синхронную операцию чтения/записи таким образом, чтобы получать общее значение времени записи и чтения данных. И чтение, и запись считаются завершенными, только в том случае, если данные были перемещены на устройство хранения и вся информация файловой системы по операции ввода/вывода была обновлена.
Файловый системы реального времени обычно очень просты. Файлы должны быть непрерывными, для того чтобы не возникала ситуация непредвиденных перемещений головки диска на другие секторы или цилиндры, что в противном случае добавило бы непредсказуемости к системе.
QNX Neutrino RTOS v6.2 поддерживает несколько видов файловых систем, от простой до сложной. Собственная файловая система (Fsys) включает в себя поддержку директорий, символьных ссылок и даже индивидуальные права доступа к файлам для индивидуальных пользователей или групп пользователей. Более того, файлы не обязательно должны быть непрерывными. Большие файлы могут располагаться в нескольких областях. Под областью здесь понимается непрерывное множество блоков на диске. Однако, области, в которых располагается файл, не обязательно будут непрерывными.
Факт, подтверждающий прерывистость файлов доказывается в разделе 4.8.4, в котором обрабатывается чтение 1 блока (512 байтов). Средняя операция чтения занимает около 150 мкс, но периодически повторяющаяся операция чтения занимает от четырех до пяти раз больше.
Те же рассуждения могут быть проведены для операции записи. При использовании данной файловой системы при разработке приложений реального времени, необходимо учитывать данную фрагментацию и убедиться в том, что время перехода к новой области ограничено.
Также QNX NEUTRINO RTOS v6.2 поддерживает неструктурированную файловую систему, представляющую собой случайно доступную последовательность байтов, не имеющую никакой определенной структуры. Это предоставляет возможность более предсказуемого получения данных, но за распознавание этой структуры становятся ответственными сами приложения.
4.8.1 Создание
- Число нитей: 1
- Модель памяти: d
| Число опытов | Минимальное (мкс) | Максимальное (мкс) | Среднее (мкс) | | 250 | 6207 | 11596 | 6575 |
|
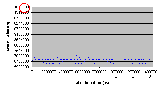
Рис. 4.8-1 FS-a-1.d
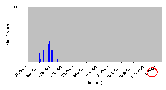
Рис. 4.8-2 FS-a-1.d - распределение частоты
4.8.2 Удаление
- Число нитей: 1
- Модель памяти: d
| Число опытов | Минимальное (мкс) | Максимальное (мкс) | Среднее (мкс) | | 250 | 561 | 759 | 578 |
|
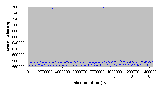
Рис. 4.8-3 FS-b-1.d
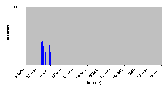
Рис. 4.8-4 FS-b-1.d - распределение частоты
4.8.3 Чтение – 1 байт
- Число нитей: 1
- Модель памяти: d
- Число байтов: 1 байт
| Число опытов | Минимальное (мкс) | Максимальное (мкс) | Среднее (мкс) | | 500 | 91 | 116 | 93 |
|
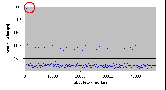
Рис. 4.8-5 FS-c-1.d.1
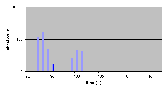
Рис. 4.8-6 FS-c-1.d.1 - распределение частоты
4.8.4 Чтение – 512 байтов
- Число нитей: 1
- Модель памяти: d
- Число байтов: 1 блок (512 байтов)
| Число опытов | Минимальное (мкс) | Максимальное (мкс) | Среднее (мкс) | | 500 | 114 | 440 | 123 |
|
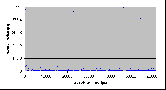
Рис. 4.8-7 FS-c-1.d.1b
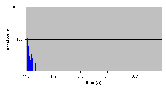
Рис. 4.8-8 FS-c-1.d.1b – распределение частоты
4.8.5 Чтение – 5120 байтов
- Число нитей: 1
- Модель памяти: d
- Число байтов: 10 блоков (5120 байтов)
| Число опытов | Минимальное (мкс) | Максимальное (мкс) | Среднее (мкс) | | 500 | 239 | 710 | 326 |
|
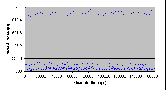
Рис. 4.8-9 FS-c-1.d.10b
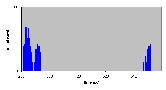
Рис. 4.8-10 FS-c-1.d.10b - распределение частоты
4.8.6 Запись – 1 байт
- Число нитей: 1
- Модель памяти: d
- Число байтов: 1 байт
| Число опытов | Минимальное (мкс) | Максимальное (мкс) | Среднее (мкс) | | 500 | 1710 | 29998 | 2340 |
|
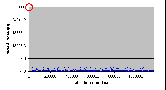
Рис. 4.8-11 FS-d-1.d.1
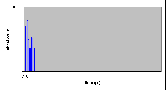
Рис. 4.8-12 FS-d-1.d.1 - распределение частоты
4.8.7 Запись – 512 байтов
- Число нитей: 1
- Модель памяти: d
- Число байтов: 1 блок (512 байтов)
| Число опытов | Минимальное (мкс) | Максимальное (мкс) | Среднее (мкс) | | 500 | 30 | 54369 | 20936 |
|
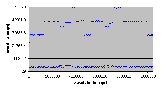
Рис. 4.8-13 FS-d-1.d.1b
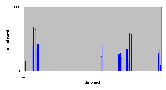
Рис. 4.8-14 FS-d-1.d.1b – Распределение частоты
4.8.8 Запись – 5120 байтов
- Число нитей: 1
- Модель памяти: d
- Число байтов: 10 блоков (5120 байтов)
| Число опытов | Минимальное (мкс) | Максимальное (мкс) | Среднее (мкс) | | 500 | 3911 | 58778 | 24519 |
|
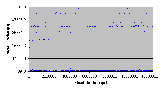
Рис. 4.8-15 FS-d-1.d.10b
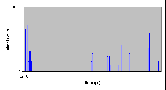
Рис. 4.8-16 FS-d-1.d.10b – распределение частоты
4.9 Сетевой стек – TCP/IP
В данном разделе рассматривается производительность и эффективность сетевого стека TCP/IP. QNX NEUTRINO RTOS v6.2 предоставляет две различных реализации стеков TCP/IP. - Полный стек TCP/IP: полная реализация стека TCP/IP.
- Компактный стек TCP/IP: сильно сокращенная реализация TCP/IP стека для систем с ограниченными ресурсами.
Поскольку тестовое приложение реализует только основные сокет-запросы, оно было запущено для каждого вида стеков для сравнения их эффективности и производительности.
Цель данного теста заключается в том, чтобы оценить частотный диапазон и использование процессора для различных размеров пакетов. Размер пакета варьируется от 1 до 2000 байтов, приращение на каждом шаге составляет 40 байтов. Для получения дополнительной информации по реализации данного теста читатель может обратиться к документу "Report definition and test plan", который находится на сайте (http://www.dedicated-systems.com/encyc/buyersguide/rtos/rtosmenu.htm).
Тесты были проведены на изолированной 10 Mbit/s изернет-сети. Отправитель блокирует Нагл алгоритм. Этот алгоритм может связывать несколько небольших отправок данных в одну большую, которая и посылается в одном TCP/IP пакете. Этот механизм значительно упрощает указанный выше протокол взаимодействия, но часто неприменим в системах реального времени из-за возникающих задержек.
4.9.1 Полный TCP/IP стек – способность приема
Рис. 4.9-1 показывает, что при увеличении размера пакета приемная способность полного TCP/IP стека достигает 1000 кБ/с. Стек использует почти 100% доступных мощностей процессора, независимо от размера пакета.
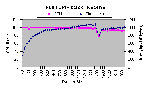
Рис. 4.9-1: Полный TCP/IP стек – способность приема
4.9.2 Компактный стек TCP/IP – способность приема
Компактный TCP/IP стек предоставляет немного меньшую производительность по сравнению с его полным аналогом, но использует меньшие мощности процессора.
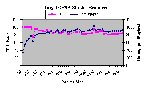
Рис. 4.9-2: Компактный TCP/IP стек – способность приема
4.9.3 Полный TCP/IP стек – способность отправки
Те же замечания, что и к тесту раздела 4.9.1 (Полный TCP/IP стек - приемная способность).
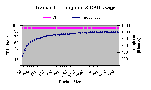
Рис. 4.9-3: Полный TCP/IP стек – способность отправки
4.9.4 Компактный TCP/IP стек – способность отправки
Те же замечания, что и в разделе 4.9.2 (Компактный TCP/IP стек - приемная способность). Способность отправки компактного стека значительно меньше, чем у его полного аналога. В общем, производительность компактного TCP/IP стека очень сильно зависит от размера пакета, что видно из рис. 4.9-4.
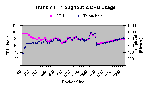
Рис. 4.9-4: Компактный TCP/IP стек – способность отправки
4.10 Порядок обслуживания прерывания по часам
В данном разделе обсуждается ISR часов. QNX NEUTRINO RTOS v6.2 доступна для различных аппаратных платформ, которые, в свою очередь, могут по разному влиять на поведение RTOS в режиме реального времени. В рассматриваемом разделе мы будем определять различия между двумя видами архитектуры целевого аппаратного оборудования: - Целевая машина, у которой прерывание часов обладает самым высоким уровнем приоритета.
- Целевая машина, у которой прерывание часов имеет не самый высокий уровень приоритета.
Обычно Intel-компьютеры (по умолчанию) относятся к первой категории. Прерывание часов аппаратно установлено на IRQ0, который по умолчанию имеет уровень приоритета выше, чем уровень приоритета любого другого внешнего прерывания. Это означает, что каждое действие в системе (включая обслуживание важных внешних аппаратных прерываний) может быть прервано обслуживанием часов. Поэтому очень важно знать максимальное время работы ISR часов, так как это время ожидания необходимо добавить ко времени ожидания обработки прерывания для получения результатов в худшем случае. В результате, система медленнее реагирует на события. Таким образом, аппаратные архитектуры, у которых прерывания таймера имеет самый высокий уровень приоритета, не являются часто используемыми в системах реального времени.
Целевые машины с архитектурами аппаратного оборудования второй категории не обязательно присваивают прерыванию часов самый высокий уровень приоритета. Таким образом, система отреагирует на другие внешние прерывания (с уровнем приоритета выше, чем у прерывания часов) как можно быстрее, поскольку их обработка не будет задержана часами. Можно предположить, что выбор подобных архитектур наиболее соответствует системам реального времени, но есть один недостаток: низкий приоритет прерывания часов может вызвать неустойчивость в синхронизации часов. Для некоторых видов приложений, в которых важна точная частота тиков часов, это может быть неприемлемым.
В разделе были выполнены два теста на изучение времени выполнения ISR часов. Главная нить каждого теста остается неизменной: повторяющееся выполнение вычисления, занимающее около 224 мкс. Затем часы прерывают главную высокоприоритетную нить, и оценивается увеличение времени вычислений. Разница между нормальным (минимальным) временем вычисления и временем вычисления в худшем случае и есть худший случай времени обработки прерывания часов (никаких других прерываний в системе не возникает).
Первый тест, результаты которого представлены в разделе 4.10.1, включает только главную нить. И, как видно из рис. 4.10-1, непрерываемые вычисления занимают 224 мкс. Время вычислений во второй серии опытов колеблется около 228 мкс, что было вызвано возникновением прерывания часов. Можно сделать следующий вывод: стандартное время выполнения ISR часов составляет приблизительно 4 мкс (на Pentium 200 MHz).
Данный тест был повторен с добавлением дополнительных нитей, выполняющих оператор "sleep", который заканчивал свое действие в середине вычислений главной нити (это похоже на установку таймера). Результаты данного тестирования не приводятся, так как добавление дополнительных нитей никак не повлияло на время выполнения ISR часов.
Двумя главными операциями, выполняемыми ISR часов, являются обновление регистра счетчика часов и управление временем истечения таймера. С каждым тиком часов регистр счетчика должен обновляться и это минимальная работа, которую ISR часов должна выполнять снова и снова. Это случай, когда выполнение ISR часов занимает 4мкс.
С другой стороны, при выполнении ISR часов обновляется регистр счетчика и возможно истекает срок по таймеру, что может привести к выполнению дополнительной работы. В некоторых системах это приводит к значительному увеличению времени выполнения ISR часов. Как было отмечено ранее, эта проблема возникает для целевых машин, у которых прерывание по часам имеет самый высокий приоритет, так как это замедляет реакцию системы на другие прерывания.
4.10.1 Clock ISR – без загрузки системы и без таймеров
- Число нитей: 1
- Модель памяти: a
| Число опытов | Минимальное (мкс) | Максимальное (мкс) | Среднее (мкс) | | 16383 | 223.9 | 230.6 | 224.8 |
|
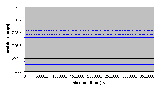
Рис. 4.10-1 ISR часов(без загрузки, без таймера)
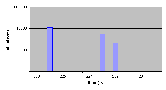
Рис. 4.10-2 ISR часов (без загрузки, без таймеров) – Покомпонентное изображение
4.11 Максимальное количество объектов
В данном разделе мы определяем, наносит ли ущерб производительности системы создание большого количества объектов (семафоров и нитей). Это реализовано путем проведения теста на время ожидания переключения между нитями с использованием 128 нитей (см. раздел 4.4) при загрузке системы большим количеством дополнительных объектов.
Для определения того, существует ли зависимость производительности системы от количества созданных объектов, результаты данного теста сравниваются с результатами того же теста, но при незагруженной объектами системе.
Максимальным числом объектов при проведении теста считается наибольшее число объектов, которое может быть создано без возникновения ошибки "недостаточный объем памяти". В идеале, результаты этого теста должны совпадать с результатами тестирования незагруженной системы.
4.11.1 Семафоры
Цель данного теста заключается в том, чтобы определить, влияет ли создание большого количества семафоров на производительность системы. Для этого проводится тест на время ожидания переключения между нитями (128 нитей) при загрузке системы семафорами.
Число семафоров, которое может быть создано в QNX NEUTRINO RTOS v6.2 без превышения размеров памяти, очень велико. Поэтому тест проводился с использованием 100,000 семафоров. Никакой полезной работы при проведении теста эти семафоры не выполняют, они просто загружены в систему.
Рисунок результатов теста представлен совместно с тестированием нитей в следующем разделе данного документа.
4.11.2 Нити
Цель данного теста заключается в том, чтобы проверить влияет ли создание большого количества нитей на производительность системы. Для этого был проведен тест времени ожидания переключения между нитями (128 нитей) при загрузке системы 10,000 дополнительных нитей.
Эти дополнительные нити не выполняли никаких действий во время проведения теста, а только были загружены в систему.
Рис. 4.11-1 Сравнительная характеристика времени переключения между нитями
Как видно из рисунка 4.11-1, минимальное, среднее и максимальное значения времени ожидания изменяются при загруженной объектами системе, но максимальное значение остается приемлемым - около 11мкс. Т.е. при загрузке системной памяти нитями не происходит значительной потери производительности.
4.12 Утечки памяти (Memory leaks)
Данный раздел определяет, приводят ли различные системные операции к утечкам памяти.
4.12.1 Создание/удаление семафоров и мьютексов
Цель данного раздела заключается в том, чтобы определить приводят ли системные операции создания и удаления семафоров и мьютексов к случаям утечки памяти. Тест реализован следующим образом (псевдокод):
LOOP 1000 times
Get Available Physical Memory
Create 100 Objects
Delete 100 Objects
END LOOP
Утечек памяти обнаружено не было.
4.12.2 Создание/удаление процессов
В данном разделе определяется, приводит ли создание и удаление процессов к утечкам памяти. Тест включает в себя родительский процесс, порождающий процесс – потомок.
В нижеследующих разделах рассматриваются четыре разновидности проведенных тестов: - Процесс–потомок не выполняет никаких действий, не размещается в памяти и не создает объекты и получает возможность корректно завершиться.
- Процесс–потомок создает несколько семафоров, которые не удаляются и корректно завершает выполнение.
- Процесс–потомок не выполняет никаких действий, не размещается в памяти и не создает объекты, но не получает возможности корректно завершиться. Вместо этого родительский процесс удаляет его во время выполнения.
- Родительский процесс удаляет процесс–потомок во время его выполнения, но до того, как процесс–потомок создал семафоры.
4.12.2.1 Нормальное завершение процесса без создания объектов
Данный тест очень похож на аналогичный тест с нитями, но вместо нитей используются процессы. Был выполнен следующий тест (псевдокод):
LOOP 1000 times
Get Available Physical Memory
Create 1 PROCESS
Sleep 10ms
CloseHandle(PROCESS) // Close the handle to the process
END LOOP
Главный цикл создает другой процесс и "засыпает" на 10мс для того, чтобы дать созданному процессу выполниться и завершиться. Создаваемый процесс содержит только одну нить, которая не производит никаких действий, только пишет один отсчет на анализатор PCI и может быть расценена как завершенная. В завершении, когда обработка процесса закончена, последовательность действий повторяется.
Утечек памяти обнаружено не было.
4.12.2.2 Нормальное завершение процесса с созданием объектов
Данный тест идентичен тесту раздела 4.12.2.1 (Нормальное завершение процесса без создания объектов), за исключением того, что создаваемый процесс создал в свою очередь 100 семафоров, не удаляемых после завершения процесса. При сравнении результатов с результатами предыдущего теста можно сделать вывод о том, что происходит с открытыми объектами при завершении процесса.
Утечек памяти обнаружено не было.
4.12.2.3 Принудительное удаление процесса без создания объектов
Данный тест идентичен тесту раздела 4.12.2.1 (Нормальное завершение процесса без создания объектов), за исключением того, что в данном случае создаваемый процесс не получает возможности корректно завершиться. Родительский процесс убивает процесс-потомок во время его выполнения.
Утечек памяти обнаружено не было.
4.12.2.4 Принудительное удаление процесса с созданием объектов
Данный тест похож на тест раздела 4.12.2.2 (Нормальное завершение процесса с созданием объектов), за исключением того, что в данном случае создаваемый процесс не получает возможности завершиться корректно. Родительский процесс убивает процесс- потомок во время его выполнения.
Утечек памяти обнаружено не было.
Далее >>>
|
 |
|

